


노엄 브라운 오픈AI 리서치 부문 부사장은 3일 서울 강남구 웨스틴 서울 파르나스에서 열린 ‘글로벌 AI 프론티어 심포지엄 2026’ 기조연설에서 기존 인공지능(AI) 평가 방식의 한계를 지적했다. AI 모델 성능을 하나의 벤치마크 점수로 비교하는 방식에서 벗어나, 추론에 투입한 시간·비용·토큰 수를 함께 봐야 한다는 주장이다.
|

그는 “오늘날 모델 평가 방식은 잘못돼 있다”며 “더 큰 규모의 테스트 시점 연산이 쓰이는 시대에는 AI 평가를 다시 생각해야 한다”고 말했다. 현재처럼 모델별 점수를 막대그래프로 비교하는 방식은 AI의 실제 능력을 충분히 보여주지 못한다는 설명이다.
브라운 부사장은 오픈AI의 최신 모델을 예로 들었다. 그는 GPT-5.5가 벤치마크 숫자만 보면 큰 도약처럼 보이지 않지만, 사용자가 직접 모델을 써본 뒤에는 체감 성능이 훨씬 높다는 평가가 나왔다고 했다. 최신 모델이 더 긴 추론 과정과 더 많은 출력 토큰을 활용할수록 성능을 크게 끌어올릴 수 있다는 설명이다.
그는 “GPT-5.5를 더 오래 생각하게 하면 되지 않느냐는 질문을 받지만, 문제는 어디까지 오래 돌려야 하느냐다”며 “최신 모델은 성능이 정체되는 지점이 멀어 기존 평가 방식으로는 실제 능력을 포착하기 어렵다”고 말했다. 과거 모델은 일정 시간 이상 추론해도 성능이 금방 정체됐지만, 최근 모델은 더 많은 시간과 연산을 투입할수록 성능이 계속 올라가는 경향을 보인다는 것이다.
브라운 부사장은 이를 시험에 비유했다. 같은 학생이라도 10분짜리 시험과 하루 동안 풀 수 있는 시험의 결과는 다를 수 있다. AI도 마찬가지로, 짧은 시간 안에 답한 결과와 며칠 동안 여러 접근법을 시도한 결과는 다를 수 있다. 시험시간을 빼고 점수만 비교하면 진짜 실력을 제대로 알기 어렵다는 의미다.
그는 사이버보안, 수학, 머신러닝 연구처럼 복잡한 문제에서는 모델이 더 오래 생각할수록 성능이 크게 개선될 수 있다고 봤다. 실제로 여러 실험에서 최신 모델은 수많은 토큰을 생성하며 문제를 풀수록 성공률이 계속 높아졌다고 소개했다. 일부 모델은 수백만·수천만 토큰을 사용한 뒤에도 성능 향상이 멈추지 않았다.
|
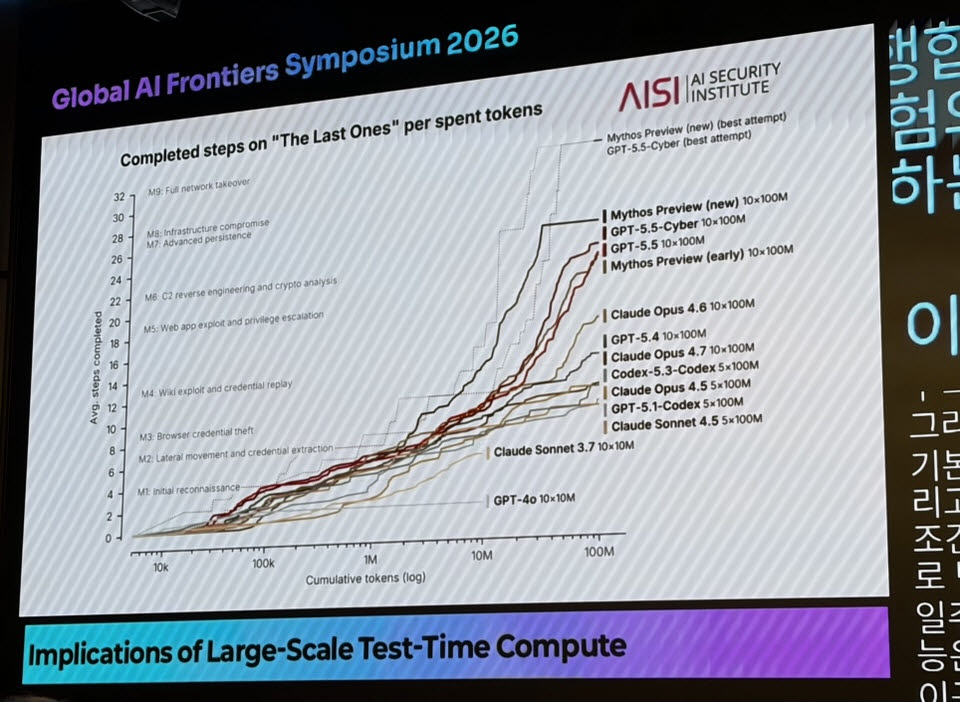
그는 AI 성능 평가도 이에 맞춰 바뀌어야 한다고 주장했다. 모델 점수를 하나의 숫자로 제시하는 대신, X축에 비용·토큰·시간을 두고 Y축에 성능을 표시하는 ‘성능 곡선’으로 평가해야 한다는 것이다. 같은 모델이라도 10달러어치 연산을 썼을 때와 100만달러어치 연산을 썼을 때의 능력이 다를 수 있기 때문이다.
안전성 평가도 마찬가지다. 브라운 부사장은 현재 많은 AI 안전성 평가는 비교적 낮은 추론 예산에서 이뤄진다고 지적했다. 이 경우 평가에서는 위험하지 않아 보인 모델도, 특정 조직이 훨씬 많은 비용과 시간을 들여 오래 돌리면 더 강력하고 위험한 능력을 보일 수 있다.
그는 “낮은 연산 예산으로 안전성 평가를 했을 때는 모델이 위험한 일을 할 수 없어 보일 수 있다”며 “하지만 누군가 훨씬 많은 시간과 비용을 들여 모델을 오래 돌리면, 평가 과정에서는 드러나지 않았던 더 강한 능력이 나타날 수 있다”고 설명했다.
브라운 부사장은 향후 AI 에이전트가 몇 시간이나 며칠을 넘어 몇 달 동안 지속적으로 작동하는 시대가 올 수 있다고 전망했다. 그는 인간 문명이 개인의 지능만으로 발전한 것이 아니라 수많은 사람이 지식을 축적하고 공유하며 발전했듯, AI도 여러 에이전트가 협력하고 지식을 공유하면 지금보다 훨씬 큰 능력을 보일 수 있다고 분석했다.
그는 “AI 연구소들은 새 모델을 공개할 때 단일 점수가 아니라 토큰, 비용, 시간에 따른 성능을 함께 공개해야 한다”며 “책임 있는 확장 정책과 안전성 기준도 테스트 시점 연산 규모를 명시적으로 반영해야 한다”고 강조했다.






